Hadoop 安装和配置(单节点)
Hadoop生态圈仍处于欣欣向荣的发展态势,不断涌现新的技术和名词。Hadoop的HDFS、YARN、MapReduce仍是最基础的部分,这篇文章记录了如何一步步在linux上安装单节点的Hadoop,之后就可以在它上面做一些练习了。截至目前(2018.7.16),Hadoop的最新版本是3.0.3,但使用最新版本的问题是:当你遇到问题时,所能找到的资料或者书籍都是针对较晚版本的。因此,对一项技术,如果没有达到特别熟悉,安装次新、或者次次新版本是一个相对稳妥的做法。所以,我选择安装的是2.9.1版本。
Hadoop有三种安装方式:独立(Standalone),单机单进程;伪分布(Pseudo-Distributed),单机多进程;完全分布(Fully-Distributed),多机多进程。这篇文章记录了伪分布模式安装的步骤。
配置运行环境
安装Java
查看:linux上安装JDK8。
配置SSH免密登录
因为只有一台主机,所以只要配置本机的ssh登录就可以了。当构建集群的时候,免密登录可以方便地使用scp工具在多个主机之间拷贝文件,从而方便部署。
安装rsync
rsync,是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件。rsync使用所谓的“rsync算法”来使本地和远程两个主机之间的文件达到同步,这个算法只传送两个文件的不同部分,而不是每次都整份传送,因此速度相当快。使用yum来进行安装:
# yum install -y ssh rsync
下载和安装
可以前往hadoop的官网获取下载链接:https://hadoop.apache.org/releases.html
本文选择安装的是2.9.1,使用下面命令进行下载:
# cd ~/downloads; \ wget http://apache.communilink.net/hadoop/common/hadoop-2.9.1/hadoop-2.9.1.tar.gz
解压缩到/opt/hadoop文件夹:
# mkdir /opt/hadoop; \ tar -xzvf hadoop-2.9.1.tar.gz -C /opt/hadoop
配置环境变量
使用vim编辑~/.bashrc文件,在最底部写入下面内容:
export HADOOP_HOME=/opt/hadoop/hadoop-2.9.1 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
然后通过source命令,使得变量立即生效:
# source ~/.bashrc
输出$PATH,看是否正确:
# echo $PATH /opt/hadoop/hadoop-2.9.1/bin:/opt/hadoop/hadoop-2.9.1/sbin:/opt/jdk/jdk1.8.0_171/jre/bin:/opt/spark/spark-2.3.1-bin-hadoop2.7/bin:/root/bin:/usr/bin:/usr/local/bin:/usr/local/sbin:/usr/sbin:
上面的PATH中,还有JAVA_HOME(/opt/jdk/jdk1.8.0_171/jre)和SPARK_HOME(/opt/spark/spark-2.3.1-bin-hadoop2.7/)。其中JAVA_HOME必须配置正确。
配置Hadoop
编辑codr-site.xml
该文件位于 $HADOOP_HOME/etc/hadoop/core-site.xml,按如下进行配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop</value> </property> </configuration>
编辑hdfs-site.xml
该文件位于 $HADOOP_HOME/etc/hadoop/hdfs-site.xml,按如下进行配置:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
编辑mapred-site.xml
这个文件需要通过 $HADOOP_HOME/etc/hadoop/mapred-site.xml.template创建(复制并重命名)。它用于将资源管理器配置为YARN。
# cd $HADOOP_HOME/etc/hadoop/; \ cp mapred-site.xml.template mapred-site.xml
编辑内容,如下所示:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
编辑yarn-site.xml
该文件位于 $HADOOP_HOME/etc/hadoop/yarn-site.xml,编辑内容如下:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
启动Hadoop
格式化namenode
第一次使用前,可以先对namenode进行格式化:
# hdfs namenode -format
运行HDFS
# start-dfs.sh
查看NameNode的Web UI
假设Hadoop安装的机器IP是192.168.1.56,那么使用浏览器打开:http://192.168.1.56:50070。可以看到下面这样的Web界面:
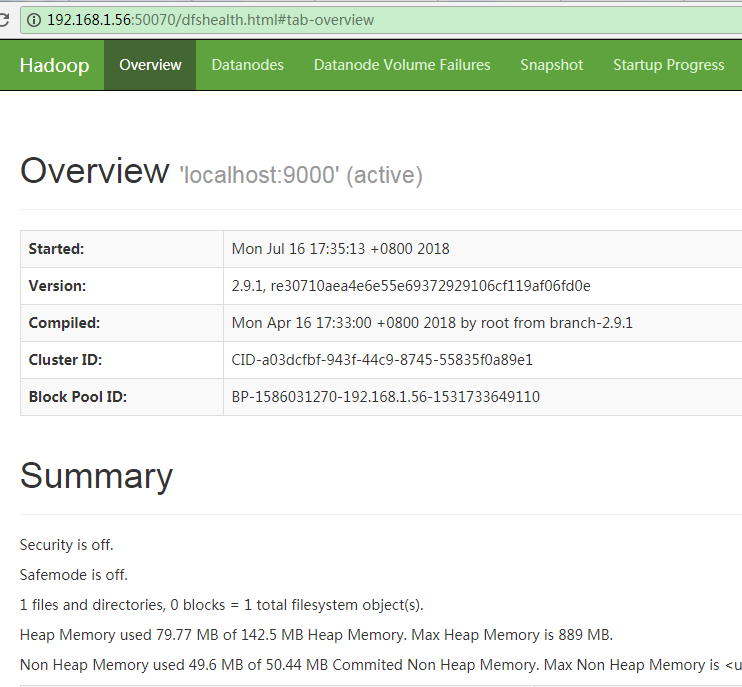
如果打不开,首先检查是不是防火墙的问题,建议可以先关闭防火墙,以排除这个因素。可以参考:linux常用命令(防火墙)
运行YARN
# start-yarn.sh
查看ResourceManager的Web UI
当启用YARN之后,就可以查看ResourceManager的Web UI了,使用浏览器打开http://192.168.1.56:8088:
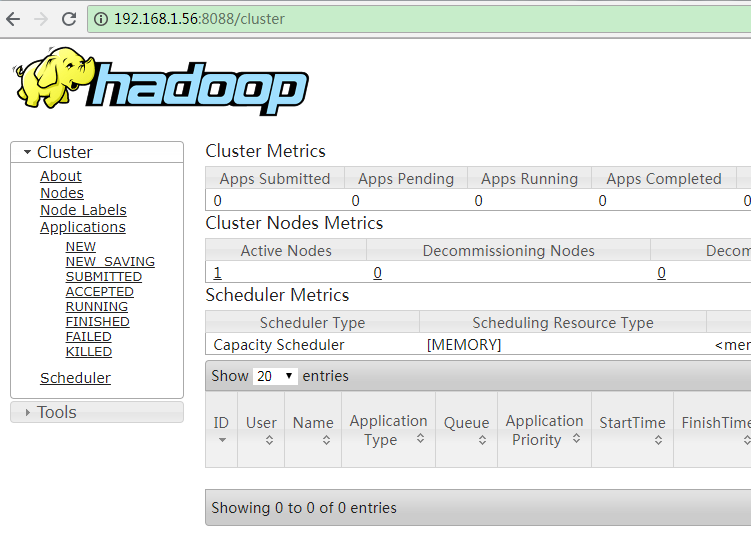
检查所有进程的运行情况
可以通过jps命令来查看进行的运行状况:
# /opt/jdk/jdk1.8.0_171/bin/jps 898 DataNode 1878 Jps 808 NameNode 1418 NodeManager 1323 ResourceManager 1103 SecondaryNameNode
根据你的java安装目录(这里是/opt/jdk/jdk1.8.0_171),上面的命令可能不同。这台主机上的$JAVA_HOME是/opt/jdk/jdk1.8.0_171/jre。
停止Hadoop
停止HDFS
# stop-dfs.sh
停止YARN
# stop-yarn.sh
至此,便完成了Hadoop单节点伪集群模式的安装。
感谢阅读,希望这篇文章能给你带来帮助!