Hadoop 配置JobHistoryServer
Hadoop自带一个Job History Server(作业历史服务,以下简称JHS),保存了作业执行的信息,例如作业名称、作业提交时间、作业启动时间、作业完成时间、作业配置信息、作业执行结果、使用的Map数、使用的Reduce数等等。JHS是一个独立的服务程序,可以运行在独立的服务器上,以分担整个集群的负载。默认情况下,JHS是不启动的。这篇文章主要介绍如何配置并运行JHS。
不启动JHS带来的问题
我的项目应用情景是这样的:每5分钟采集一次数据,并通过执行Hive的HQL语句(类似SQL,例如Insert)写入到Hadoop集群中。Hive语句最后被翻译成MapReduce作业并在集群上执行。这样相当于每5分钟就会执行一次MapReduce作业,在不启动JHS时,依然会生成作业日志,但却没有进行清理(JHS自带清理功能),于是就会越积越多。如果全部采用默认配置,并以root用户运行hadoop,那么job临时日志位置是 /tmp/hadoop-yarn/staging/history/done_intermediate/root,见下图:
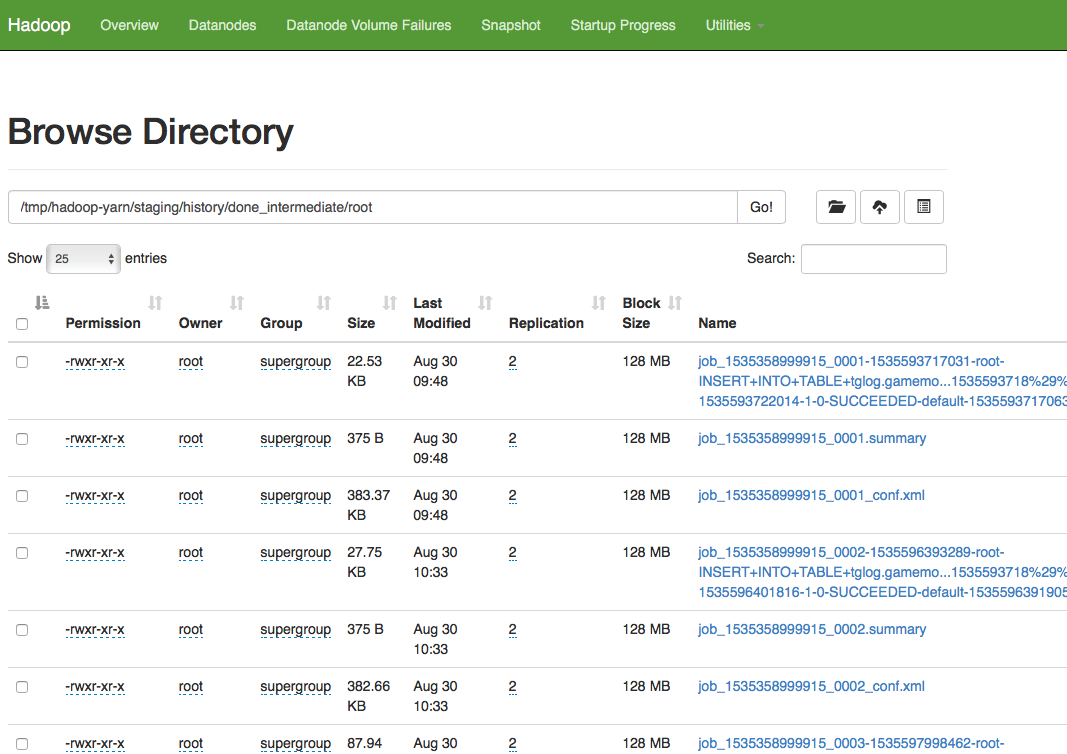
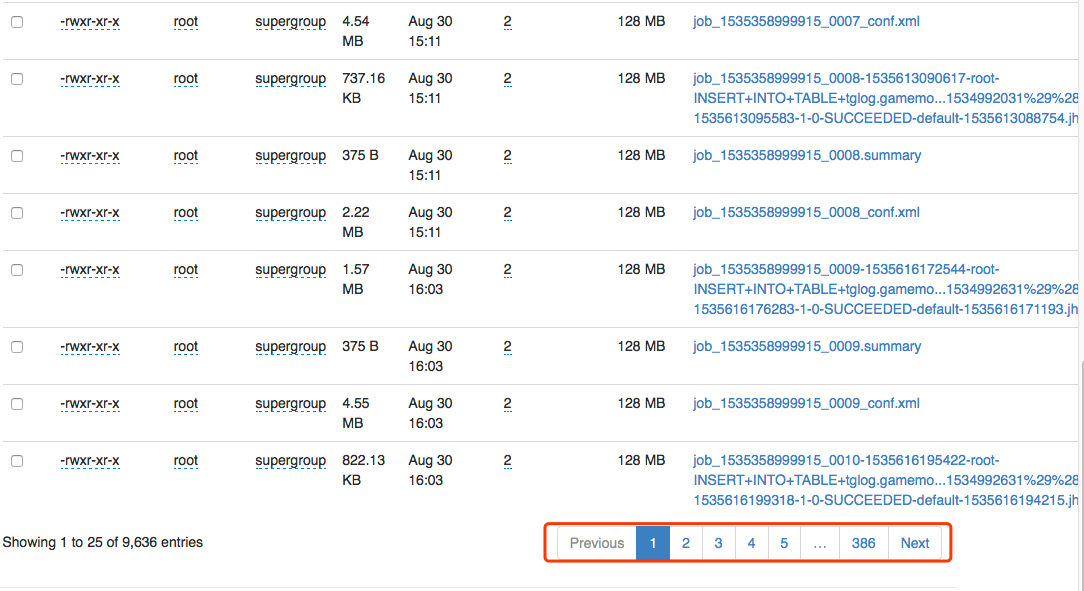
可以看到有386页,共9000多个文件,而且全是小文件。对Hadoop真是太不友好了,需要清理一下。
job日志的内容
如前面图示,在每次运行job时,生成了3个文件,类似下面这样:
job_1535358999915_0001.summary job_1535358999915_0001_conf.xml job_1535358999915_0001-1535593717031-root...SUCCEEDED-default-1535593717063.jhist
其中.summary包含了作业的基本信息:
ujobId=job_1535358999915_0001,submitTime=1535593717031,launchTime=1535593717063,firstMapTaskLaunchTime=1535593719365,firstReduceTaskLaunchTime=0,finishTime=1535593722014,resourcesPerMap=1024,resourcesPerReduce=0,numMaps=1,numReduces=0,user=root,queue=default,status=SUCCEEDED,mapSlotSeconds=2,reduceSlotSeconds=0,jobName=INSERT INTO TABLE tglog.gamemo...1535593718)(Stage-1)
conf.xml包含了作业运行时的配置信息:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><configuration> <property><name>mapreduce.jobhistory.jhist.format</name><value>json</value><final>false</final><source>mapred-default.xml</source><source>job.xml</source></property> <property><name>dfs.block.access.token.lifetime</name><value>600</value><final>false</final><source>hdfs-default.xml</source><source>job.xml</source></property> <property><name>hive.skewjoin.key</name><value>100000</value><final>false</final><source>programatically</source><source>org.apache.hadoop.hive.conf.LoopingByteArrayInputStream@600b90df</source><source>job.xml</source></property> <property><name>hive.index.compact.binary.search</name><value>true</value><final>false</final><source>programatically</source><source>org.apache.hadoop.hive.conf.LoopingByteArrayInputStream@600b90df</source><source>job.xml</source></property> <property><name>mapreduce.map.log.level</name><value>INFO</value><final>false</final><source>mapred-default.xml</source><source>job.xml</source></property> ... 省略若干行
.jhist是一个json文件,包含了作业的运行时信息,根据type进行了划分,例如 "type":"record"、"type":"JOB_INITED"、"type":"TASK_FINISHED"等等。
Avro-Json
{"type":"record","name":"Event","namespace":"org.apache.hadoop.mapreduce.jobhistory","fields":[{"name":"type","type": ...省略若干行 }}}
{"type":"JOB_SUBMITTED","event":{"org.apache.hadoop.mapreduce.jobhistory.JobSubmitted":{"jobid":"job_1535358999915_0001","jobName":"INSERT INTO TABLE tglog.gamemo...1535593718)(Stage-1)", ... 省略若干行 }}}
{"type":"JOB_QUEUE_CHANGED","event":{"org.apache.hadoop.mapreduce.jobhistory.JobQueueChange":{"jobid":"job_1535358999915_0001","jobQueueName":"default"}}}
{"type":"JOB_INITED","event":{"org.apache.hadoop.mapreduce.jobhistory.JobInited":{"jobid":"job_1535358999915_0001","launchTime":1535593717063,"totalMaps":1,"totalReduces":0,"jobStatus":"INITED","uberized":false}}}
{"type":"TASK_STARTED","event":{"org.apache.hadoop.mapreduce.jobhistory.TaskStarted":{"taskid":"task_1535358999915_0001_m_000000","taskType":"MAP","startTime":1535593717090,"splitLocations":"hadoop03"}}}
{"type":"MAP_ATTEMPT_STARTED","event":{"org.apache.hadoop.mapreduce.jobhistory.TaskAttemptStarted":{"taskid":"task_1535358999915_0001_m_000000","taskType":"MAP"... 省略若干行 }}}
{"type":"MAP_ATTEMPT_FINISHED","event":{"org.apache.hadoop.mapreduce.jobhistory.MapAttemptFinished":{"taskid":"task_1535358999915_0001_m_000000","attemptId":"attempt_1535358999915_0001_m_000000_0","taskType":"MAP" ... 省略若干行]}}}
配置JHS
在启动JHS前,需要先对其进行配置,主要的几个配置项及其默认值如下,编辑 $HADOOP_HOME/etc/hadoop/mapred-site.xml 进行配置:
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.cleaner.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.cleaner.interval-ms</name>
<value>86400000</value>
</property>
<property>
<name>mapreduce.jobhistory.max-age-ms</name>
<value>604800000</value>
</property>
<property>
<name>mapreduce.jobhistory.move.interval-ms</name>
<value>180000</value>
</property>
几个主要配置项的说明:
| 配置项 | 默认值 | 设置值 | 说明 |
|---|---|---|---|
| mapreduce.jobhistory.address | 0.0.0.0:10020 | 运行JHS的主机名:10020 | IPC host:port,默认0.0.0.0为本机 |
| mapreduce.jobhistory.webapp.address | 0.0.0.0:19888 | 运行JHS的主机名:19888 | JHS WebUI host:port,默认0.0.0.0为本机 |
| yarn.app.mapreduce.am.staging-dir | /tmp/hadoop-yarn/staging | 保留默认值 | 提交任务时的staging目录。这个是基础目录 |
| mapreduce.jobhistory.intermediate-done-dir | ${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate | 保留默认值 | 任务执行的中间结果,基于yarn.app.mapreduce.am.staging-dir |
| mapreduce.jobhistory.done-dir | ${yarn.app.mapreduce.am.staging-dir}/history/done | 保留默认值 | 已完成作业的存放目录,基于yarn.app.mapreduce.am.staging-dir |
| mapreduce.jobhistory.cleaner.enable | true | 保留默认值 | 是否开启hisotry清理器 |
| mapreduce.jobhistory.cleaner.interval-ms | 86400000 | 保留默认值(1天) | 多久执行一次清理,默认是一天。只会清理创建日期超过mapreduce.jobhistory.max-age-ms的文件。 |
| mapreduce.jobhistory.max-age-ms | 604800000 | 保留默认值(1周) | 在hisotry清理器运行时,如果文件创建日期超过此值,则会被清理掉 |
| mapreduce.jobhistory.move.interval-ms | 180000 | 保留默认值(3分钟) | 将intermediate-done-dir中的文件转移到done-dir的时间间隔 |
可以看到以上配置大多都可以采用默认值,需要改一下的主要就是:mapreduce.jobhistory.address和mapreduce.jobhistory.webapp.address了。其他的列出来只是作为参考,可能会用到。
启动Job History Server
修改好配置后,在想要运行JHS的节点上,使用下面的脚本启动JHS。
# $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/hadoop-2.9.1/logs/mapred-root-historyserver-hadoop01.out
之后执行下jps,可以看到服务已经启动。
# jps 2443 JobHistoryServer
假设主机地址是 192.168.0.10,从浏览器打开192.168.0.10:19888,可以看到下面的界面:
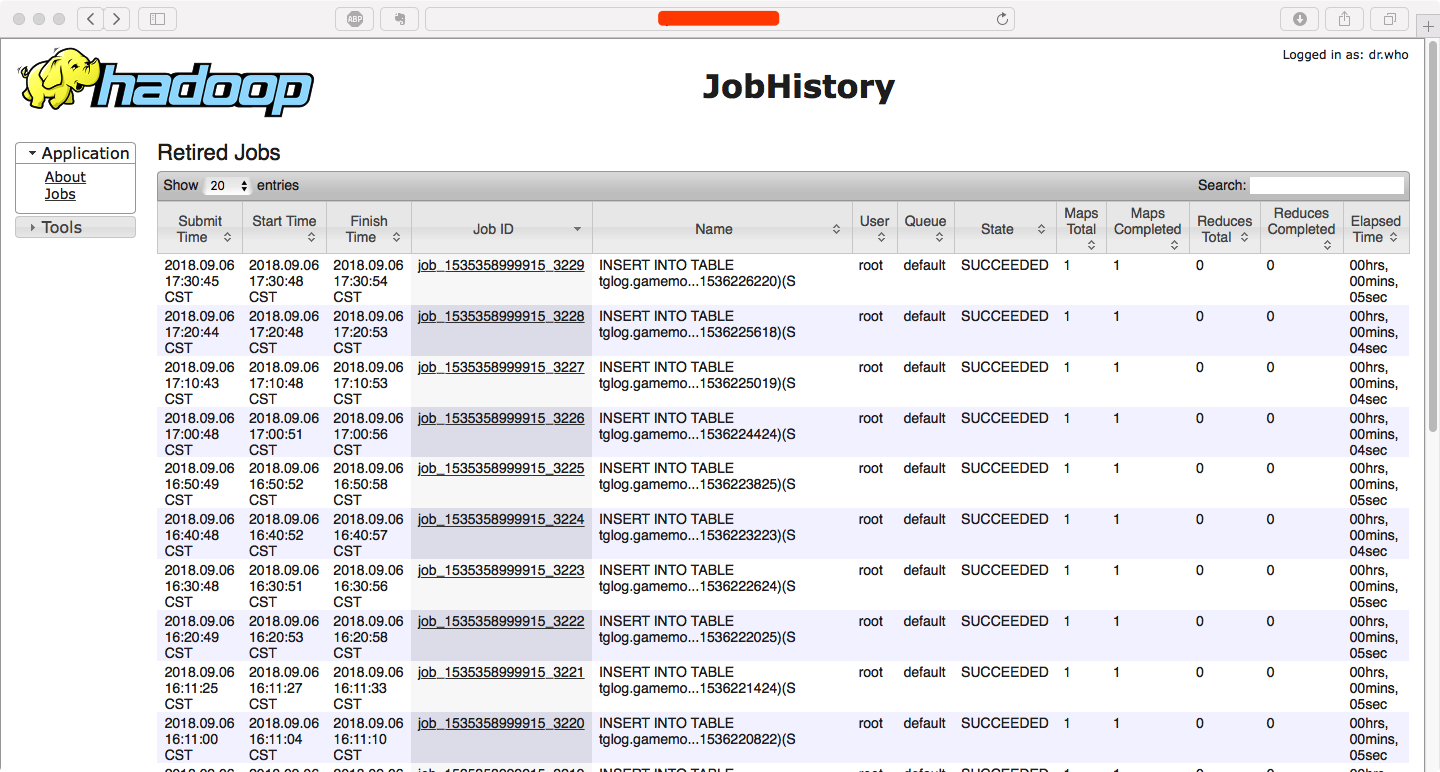
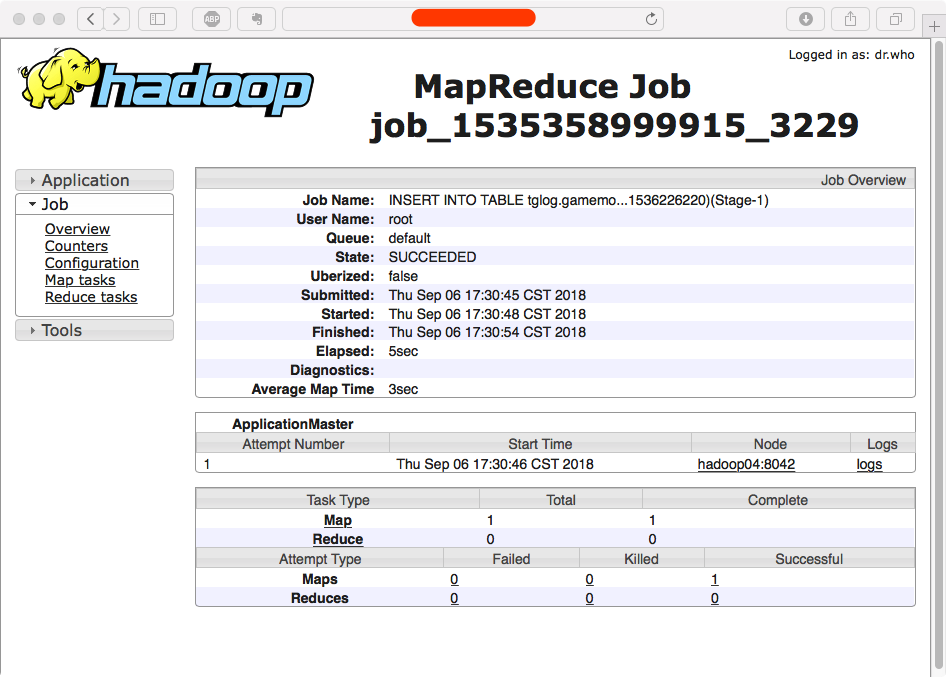
点击Job链接的标题进入后,可以查看作业详情。左侧菜单还可以查看配置信息,以及分别查看Map和Reduce,这里就不再演示了。
再次浏览HDFS上的文件,发现多了一个done文件夹,没有启动JHS前,只有一个done_intermediate文件夹。
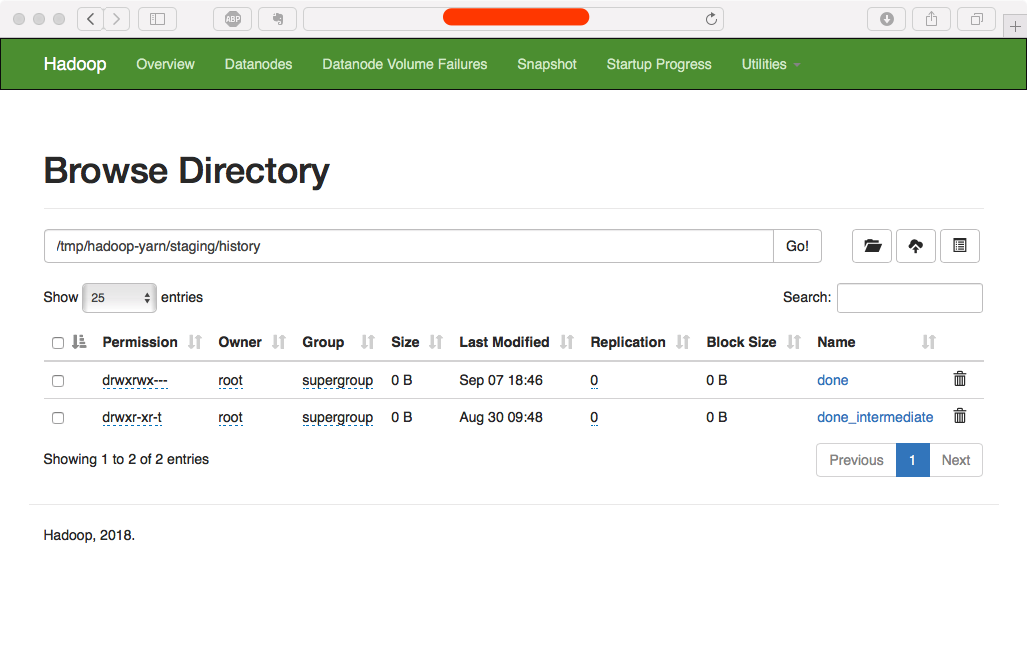
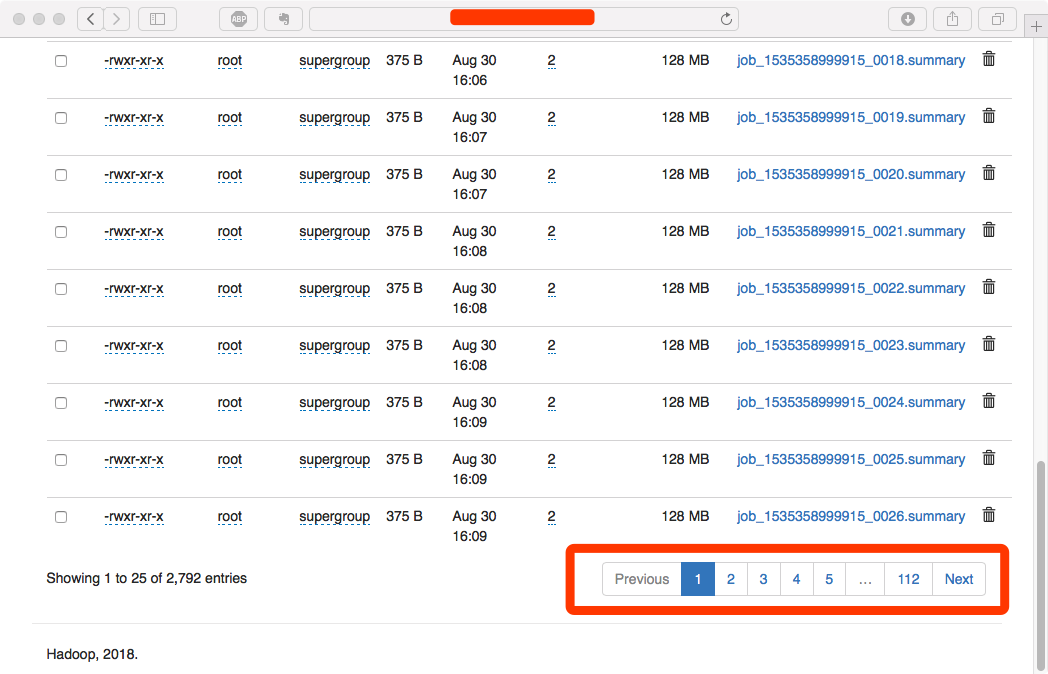
再次进入到done_intermediate下,看到文件由380多页减少到112页(减少的部分挪动到了done文件夹,保留的则是3天之前产生的文件)。
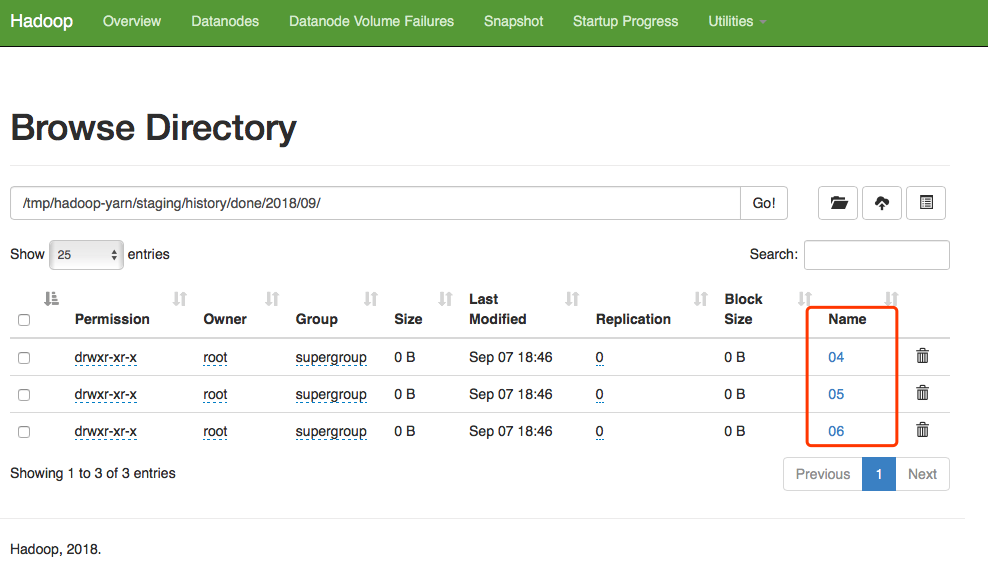
进入done文件夹下,可以看到文件已经根据年月日进行了分类,以避免单个文件夹下产生过多文件。因为我设置了只保留3天的记录,即mapreduce.jobhistory.max-age-ms设置为259200000,因此在done/2018/09下只有04、05、06三个文件夹。
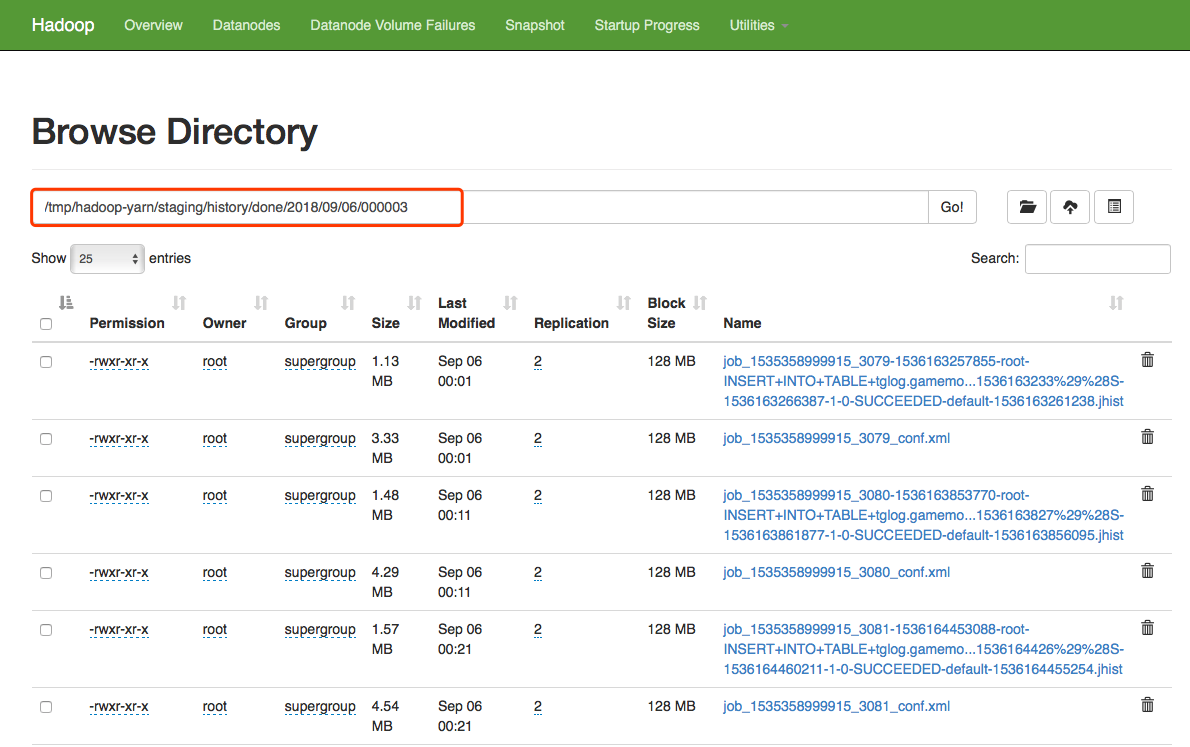
在底层文件夹,可以看到日志文件:
关闭Job History Server
执行下面的脚本,以关闭JHS。
# $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
至此,我们就完成了Hadoop集群Job History Server的配置。配置它,一方面方便查看MapReduce作业的执行情况;另一方面,可以清理作业产生大量的日志文件。
感谢阅读,希望这篇文章能给你带来帮助!