Kafka Connect 基本概念
搭建好了Kafka集群以后,最常见的两个需求就是:1、将数据从数据源采集并发送到Kafka的topic中;2、将数据从Kafka中取出,(进行运算后),然后再转存到其他的位置。完成这一工作,通常我们会使用各种语言的kafka客户端(Kafka client),调用相应的API,来完成读写kafka的操作。因为这种操作是非常常见的,因此kafka包含了一个名为Kafka Connect的组件,专门来完成这项工作。
各种语言版本的kafka客户端地址是:https://cwiki.apache.org/confluence/display/KAFKA/Clients
kafka Connect 的官方文档已经非常详尽了,没有必要复述(或者“翻译”?)一遍。因为后续文章中会提到Kafka Conncet中的一些重要概念和名词,因此这篇文章仅就这些概念简要地说明一下。官方文档关于Kafka connect的地址如下:
confluent是kafka的创始人从LinkIn出来后成立的公司,围绕kafka提供企业服务。
在没有kafka connect时,一个简化的、典型的流程图可能是这样的:
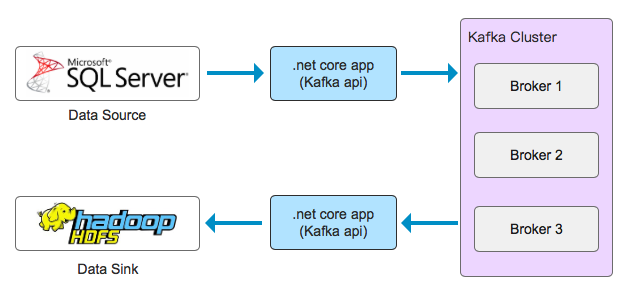
使用kafka connect,就替换了之前 .net core app(也可以是java app、go app等)的位置,重要的是kafka connect可以以集群的方式部署,并提供容错性:
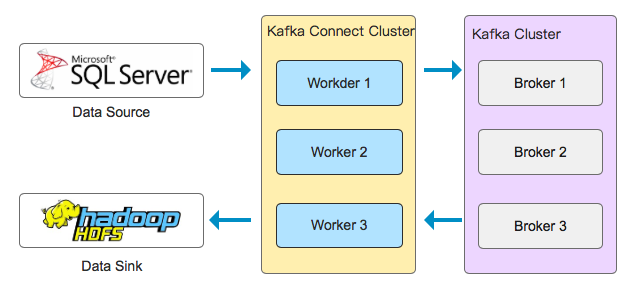
这里面的一些重要概念如下:
Data Source
数据源,各种数据存储都可以作为数据源,包括但不限于关系型数据库、文件系统、消息队列等。
Data Sink
数据池,各种数据存储都可以作为数据池,包括但不限于关系型数据库、HDFS、HBase、MongoDB、Console控制台等。Connector
有静态和动态两个概念,有点类似于代码和进程的关系。
静态概念:Connector就是可重用的java包(jars),此时也叫做connector plugin。可以自行开发,也可以使用第三方已经开发好的。例如confluent的connector下载地址是:www.confluent.io/hub。
动态概念:当前运行着的connector实例(包含了task和用户配置)。
Source Connector
从Data Source中获取数据,并写入Kafka。
Sink Connector
从Kafka中读取数据,并写入Data Sink。
Task
Connector有其 自身配置,例如group.id,将多个connector分为同一组;bootstrap.servers表明kafka的位置。
Connector还有 用户配置,用来配置其所执行的Task。
Connector可以只用其 自身配置 运行,此时其不包含任何task。当向Connector提交用户配置时,自动就运行了一个task。通常一个Connector包含一个Task。
Connector和Task分离的方式,便于进行容错:当一个worker失效时,会自动将task转移到其他worker上。
Worker
Connector和Task都是逻辑单元,它们都必须在进程内执行,这些进程称为workers。
Worker有两种部署方式,一种Standalone,一种Distributed。
当使用Standalone时,connector自身配置和用户配置同时加载,并捆绑在同一进程。
当使用Distributed时,connector先使用自身配置启动(此时没有运行任何task),然后再通过REST API提交用户配置,启动Task。
感谢阅读,希望这篇文章能给你带来帮助!