clickhouse中使用AggregatingMergeTree表引擎
最近一段时间,开发一个数据分析系统,使用Clickhouse作为数据仓库,完成对数据的存储、查询和统计。关于Clickhouse的介绍,可以参看它的官网:https://clickhouse.com/。或者是之前发表的这篇博文:ClickHouse原理解析与应用实践。这篇文章只介绍它众多表引擎当中,比较常用的一种:AggregatingMergeTree。
如果大家之前接触过数据统计方面的系统,就会了解到这样一种常见的方式:定时、按固定维度,对明细数据进行统计查询(聚合+分组),然后将统计结果存储在所谓的“统计表”中,后续业务上的查询,则针对这张“统计表”来进行。相对于存储原始数据的“明细表”,这张“统计表”要小得多,从而可以大幅提高查询的效率。
这种方式的问题主要有两个:
- “维度爆炸”,即无法穷尽所有可能的维度,或是如果穷尽所有维度,则会带来统计表的数目爆炸式增长。所以通常情况下,这种方式仅针对常见的维度进行统计,例如按日、周、月这样的时间维度,或者按渠道这样的用户来源维度。当遇到不支持的维度时,还是需要去查询明细。
- 实时性不佳,通常是按天,按小时来进行统计的,不适用实时在线查询(在统计周期比较短的情况下,例如十分钟,仅得到一个近似“实时”的结果)。
Clickhouse的优势就在于大数据量的高效、快速查询,从而在大多数情况下,直接查询明细就可以了,不再需要使用这种定时统计的方式。然而,在数据规模异常庞大的情况下,在Clickhouse中,也依然可以使用上面的方式。不仅如此,还提供了一个专门的表引擎:AggregatingMergeTree,可以极大简化“统计表”的创建过程,而且统计结果差不多是实时同步到“统计表”中的。
它的使用步骤通常是这样的:
- 建立一个以 AggregatingMergeTree 为表引擎的物化视图,这个视图是实际包含数据的,并按照SQL语句的规则,将底层的原始明细表,自动地以 聚合+分组 的方式,加工后同步过来;
- 因为 AggregatingMergeTree 的字段类型是特殊类型,不能直接查询,所以在第1步建立的视图之上,建立一个普通的常规视图(相当于存储了的SQL语句),用来解析第1步视图中的字段。
1. 创建明细表:user_order
我们通过一个实例来演示这一过程,首先创建一张基础数据表,通常也叫做明细表:
drop table if exists user_order;
create table user_order
(
user_id String,
event_date String,
amount Int32
) ENGINE = MergeTree()
ORDER BY (user_id, event_date)
这是一个简化的订单表,包含的字段含义如下:user_id用户ID、event_date支付日期,amouont支付金额。现在假设有这样一个需求:统计用户的 最小付款金额、最大付款金额 以及 付款总额,那么就可以像下面这样创建一个物化视图:
2. 创建基于 user_order 的物化视图,注意表引擎为:AggregatingMergeTree
drop view if exists user_order_a; CREATE MATERIALIZED VIEW if not exists user_order_a ENGINE = AggregatingMergeTree() ORDER BY(user_id) POPULATE AS select user_id, sumState(amount) sum_amount, minState(amount) min_amount, maxState(amount) max_amount from user_order group by user_id
物化视图和普通视图的区别是:物化视图包含了实际的数据,相当于上面说的“统计表” ;而普通视图仅保存了SQL查询语句。
注意这个视图的字段调用了 *State 格式的函数,对于聚合的字段,其类型为AggregateFunction,它能够以二进制的形式存储中间状态结果。在插入时,需要调用*State格式的函数,例如上面的sumState、minState、maxState;而在查询时,则需要调用 *Merge函数。为了查询方便,我们后面会再建一个 user_order_v 视图,来对这张视图进行查询。
AggregateFunction和Int8、String一样,是一种数据类型,只不过它比较特殊,关于AggregateFunction的详细介绍,可以查看这里:AggrageteFunction类型
3. 创建基于 user_order_v 的视图,方便对第2步创建的视图进行查询:
drop view if exists user_order_v; create view user_order_v as select user_id, sumMerge(sum_amount) sum_amount, minMerge(min_amount) min_amount, maxMerge(max_amount) max_amount from user_order_a group by user_id
注意在这一步当中,我们调用了*Merge系列的函数,且基于user_order_a中的user_id进行了聚合查询。为什么这里还要再一次group?后面进行数据插入测试时,就明白了。
这两张视图名字很接近,可能容易混淆,后缀 _a 代表 Aggregating,说明这是一个 AggregatingMergeTree引擎的视图; 后缀 _v 代表 View,说明这是一个普通的常规视图(仅保存了SQL语句)。
4. 插入数据进行测试
接下来我们插入一些数据进行测试:
insert into user_order(user_id, event_date, amount)
values
('user1', '2022-01-01', 10),
('user1', '2022-01-01', 1),
('user1', '2022-01-01', 5)
当我们像这样一次插入多行数据时,数据再进入user_order_a之前会先按照视图的定义进行一次聚合,所以插入完成后,如果我们直接查询 user_order_a 视图,会看到下面的结果:
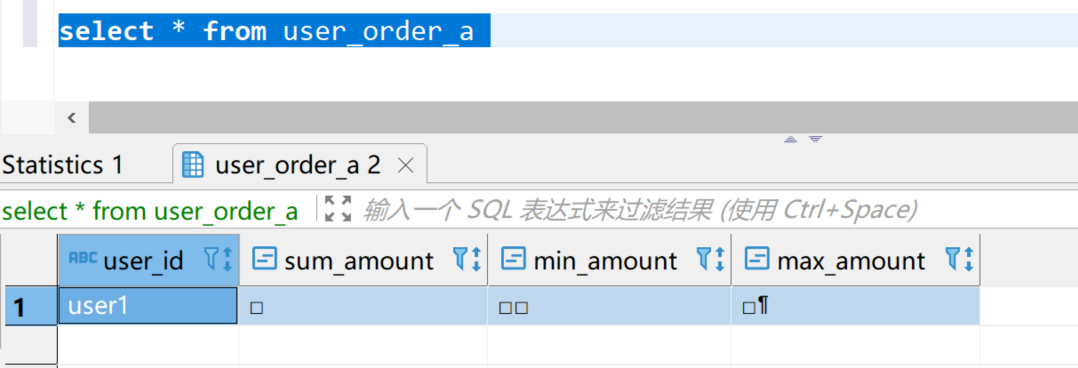
可以看到数据已经被聚合成了一行。另外注意到聚合字段无法直接看到结果,因为我们没有调用*Merge行数。
接下来,我们分次插入多行数据:
insert into user_order(user_id, event_date, amount)
values('user1', '2022-01-01', 2);
insert into user_order(user_id, event_date, amount)
values('user1', '2022-01-01', 4);
insert into user_order(user_id, event_date, amount)
values('user1', '2022-01-01', 6);
...
然后再次查询 user_order_a,会看到新插入的数据,并没能和历史数据再次聚合。
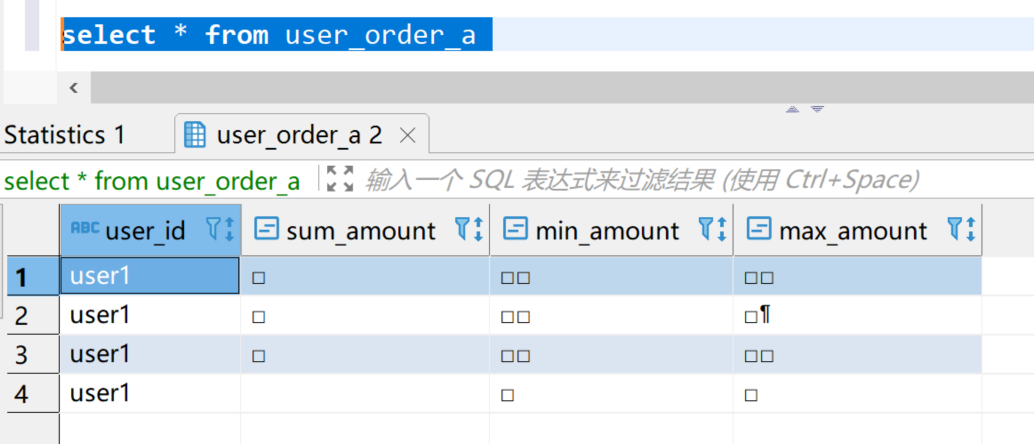
但是且慢,MergeTree系列的引擎会在后台一个不确定的时间完成聚合,那么过一会是否会再次聚合呢?确实如此,等待1分钟后,再次插入一条数据,然后查询user_order_a,会发现单次插入的多行数据,也已经被聚合了。
5. 查询user_order_v视图
这样,我们就明白了创建user_order_v视图的必要性:
- user_order_a的聚合并不是一个“完全”的聚合,它是一个非实时的聚合,会有一个尚未完成聚合的中间过程,如果此时直接取user_order_a的结果,那么就会得到部分“未聚合”的数据
- 因为直接查user_order_a,没有调用*Merge函数,也就没有获取到我们需要的实际数值。为了上层业务方便起见,我们也需要再另外创建一个基于它的查询视图。
现在查询user_order_v视图,可以看到下面的结果:
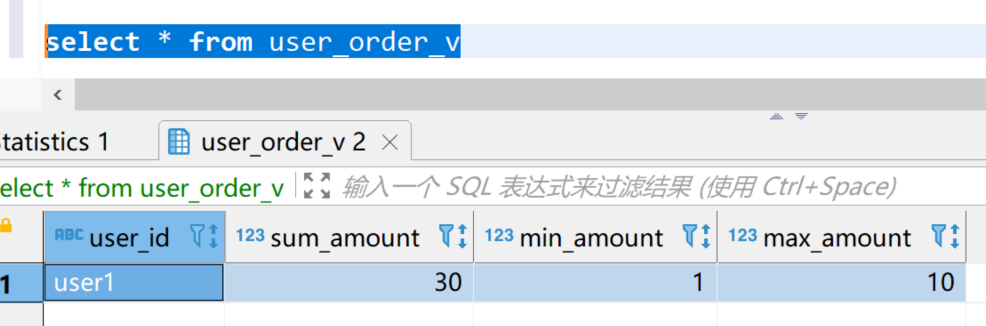
此时,通过创建user_order_a和user_order_v这一组视图,就完成了我们预期的效果,后续的查询,仅需要针对user_order_v进行即可。
总结
这篇文章以一个简化了的,生产中常见的例子,简要介绍了MergeTree表引擎家族里 AggregatingMergeTree 的用法。
感谢阅读,希望这篇文章能给你带来帮助!