Hive 安装和配置
直接通过MapReduce来对存储在Hadoop HDFS上的数据进行查询和分析比较繁琐而且还需要编程。Hive是一个数据仓库系统,构建在HDFS之上,它提供了类似SQL的语法(HQL),可以将HQL翻译成MapReduce作业进行查询,使得对数据的管理和检索更为便利。
这篇文章记录了如何在linux上安装hive。因为hive基于Hadoop,所以需要先安装Hadoop,如果你还没有安装Hadoop,可以参考linux上安装和配置Hadoop(单节点)进行安装。
下载和安装hive
前往Apache的官方下载地址:https://hive.apache.org/downloads.html,经历两个二级下载页后,获得到最终的下载地址。
登录linux系统,进入~/downloads文件夹,使用wget命令,下载安装包。这里安装的是次新版本2.3.3。
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz
使用tar命令安装至/opt文件夹
# tar zxvf apache-hive-2.3.3-bin.tar.gz -C /opt
配置PATH环境变量
使用vim编辑~/.bashrc,加入HIVE_HOME环境变量,将下面的语句复制到~/.bashrc的底部。
export HIVE_HOME=/opt/apache-hive-2.3.3-bin export PATH=$PATH:$HIVE_HOME/bin
启动Hive命令行
直接在控制台输入hive,即可启动hive。
# hive Logging initialized using configuration in jar:file:/opt/hive/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive>
完成后进入到hive的命令行界面。输入exit;或者按Ctrl+C则可以退出。
可以看到上面有一句话:Hive-on-MR is deprecated in Hive 2 ...,意思是说Hive 2版本之后可以使用新的计算引擎(例如spark和tez),Hive默认的计算引擎仍然是MapReduce,大家都知道MapReduce的执行速度是非常慢的。
执行第一个Hive查询
使用下面的命令,查看现有的数据库:
# show databases; OK default Time taken: 0.042 seconds, Fetched: 1 row(s)
会看到有一个默认的default数据库。
异常:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
执行 show databases; 后,你可能会遇到这个异常。解决办法是:1、先退出hive,然后删掉metastore_db文件夹,可以使用下面的命令找出metastore_db的位置:
# find / -name metastore_db /root/metastore_db
我是以root用户安装的hive,在我的主机上,这个目录位于/root下。使用rm命令删除之:
# rm -fR /root/metastore_db
这个metastore_db出现的位置为你执行hive命令的当前文件夹。所以每次执行hive时最好进入同一个文件夹,否则就会创建很多个metastore_db,然后再次出现上面的异常。
2、进入/root文件夹(或者是刚才find命令找出的metastore_db的上级目录),使用schematool工具重建metastore_db:
# schematool -initSchema -dbType derby Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting metastore schema initialization to 2.3.0 Initialization script hive-schema-2.3.0.derby.sql Initialization script completed schemaTool completed
执行完成后会重新创建一个metasotre_db文件夹。
metasotre_db保存了hive的元信息,也就是使用hive创建了哪些数据库、每个库中包含哪些表,诸如此类。
重新进入hive命令行,再次执行show databases;,正常的话可以看到返回结果。
默认情况下hive使用derby数据库将元信息保存在本地,一种更常见的做法是保存到mysql数据库,具体操作可以查看这里:配置Hive使用MySql存储元数据。
通过Hadoop HDFS查看数据库文件
除了使用default默认库以外,HIVE提供了很多DDL语句对数据结构进行创建、更改和删除。具体可以参看:LanguageManual DDL。
下面使用create database 命令创建一个叫做tglog_aw_2018的新数据库:
hive>> create database tglog_aw_2018; OK Time taken: 0.191 seconds
那么这个数据库文件创建到哪里去了呢?可以查看 $HIVE_HOME/conf/下的hive-default.xml.template,它是Hive的默认配置文件。如果想要重写配置,则可以在$HIVE_HOME/conf下新建一个hive-site.xml文件。在hive-default.xml.template中搜索hive.metastore.warehouse.dir配置项,可以看到如下的配置:
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property>
说明我们的数据库文件位于/user/hive/warehouse文件夹下。
hive-default.xml.template这个文件很大,有5959行,如果在linux上使用cat命令输出会很难阅读,可以使用FTP工具下载到windows系统上,然后选择自己喜欢的编辑器进行查看。
需要注意的是:这个/user/hive/warehouse并不是linux系统上的文件夹,而是位于HDFS上。因此如果要查看这个文件夹,可以通过下面的命令:
# hdfs dfs -ls /user/hive/warehouse Found 1 items drwxrwxrwx - root supergroup 0 2018-07-17 20:16 /user/hive/warehouse/tglog_aw_2018.db
也可以通过HDFS NameNode的Web UI进行查看:
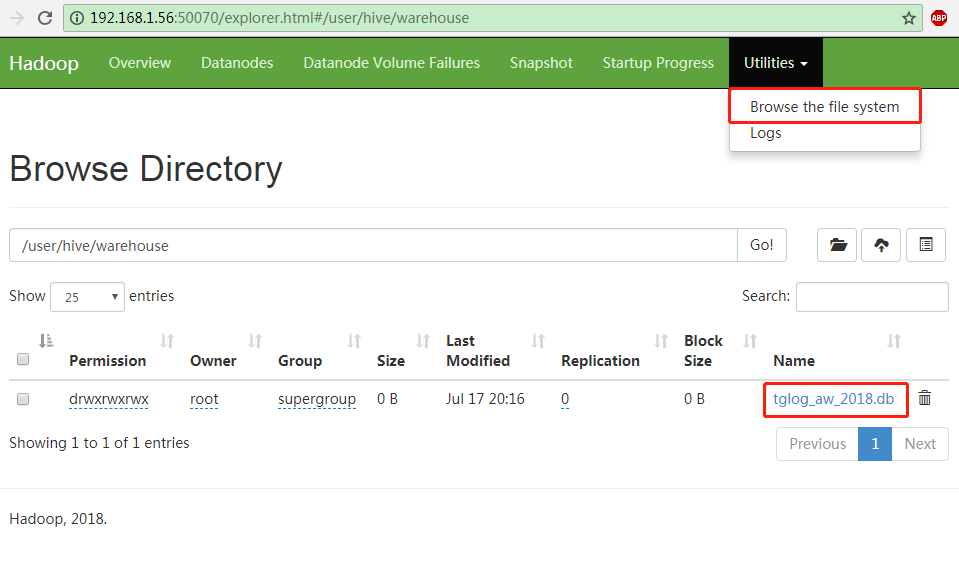
至此,就可以通过命令行来对Hive进行操作管理了。接下来,需要深入地去学习Hive的“SQL语句”,除此以外,还要掌握通过编程的方式对Hive进行操作。
感谢阅读,希望这篇文章能给你带来帮助!