Hive 使用.net通过odbc进行访问
在 写入数据到Hive表(命令行) 这篇文章中,我们通过命令行的方式和hive进行了交互。但在通常情况下,是通过编程的方式来操作Hive,Hive提供了JDBC和ODBC接口,因为公司的数据处理程序是使用.net开发并运行在windows server上的,因此这篇文章将介绍如何通过ODBC来访问Hive。
ODBC:Open Database Connectivity,开放数据库连接,是微软开放服务结构(WOSA,Windows Open Services Architecture)中有关数据库的一个组成部分,它建立了一组规范,并提供了一组对数据库访问的标准API(应用程序编程接口)。这些API利用SQL来完成其大部分任务。
JDBC:Java Database Connectivity,Java数据库连接,是用于Java编程语言和数据库之间的数据库无关连接的标准Java API。
配置hive-site.xml
hive-site.xml是Hive的配置文件,位于$HIVE_HOME/conf文件夹下,在其中添加如下配置:
<property> <name>hive.server2.authentication</name> <value>NONE</value> <description> Expects one of [nosasl, none, ldap, kerberos, pam, custom]. Client authentication types. NONE: no authentication check LDAP: LDAP/AD based authentication KERBEROS: Kerberos/GSSAPI authentication CUSTOM: Custom authentication provider (Use with property hive.server2.custom.authentication.class) PAM: Pluggable authentication module NOSASL: Raw transport </description> </property>
远程访问Hive,有好几种身份验证方式,因为我们的Hive服务仅在局域网中访问,简单起见,可以配置为NONE,也就是不进行身份验证,NONE也是hive.server2.authentication的默认值。
确认hiveserver2服务已经运行
hive需要先作为服务运行起来,第三方应用才可以进行连接,使用下面的命令启动hive服务:
# hive --service hiveserver2 2018-07-25 11:40:51: Starting HiveServer2
这个服务的默认端口号是10000。同时,还提供了一个web UI,默认端口号是10002,可以通过浏览器直接访问:
下载、安装和配置ODBC Connector
可以从这里下载各个版本的HIVE ODBC:http://archive.mapr.com/tools/MapR-ODBC/MapR_Hive/
Windows上odbc安装和配置说明:Install the Hive ODBC Connector on Windows
windows上的安装很简单,一路next,安装完成后从“开始”菜单中找到:MapR Hive ODBC Connector 2.1 (64-bit),打开 64-bit ODBC Administrato,可以看到下面的界面:
按照下图这样配置,注意修改Hosts为运行Hive服务的主机IP:
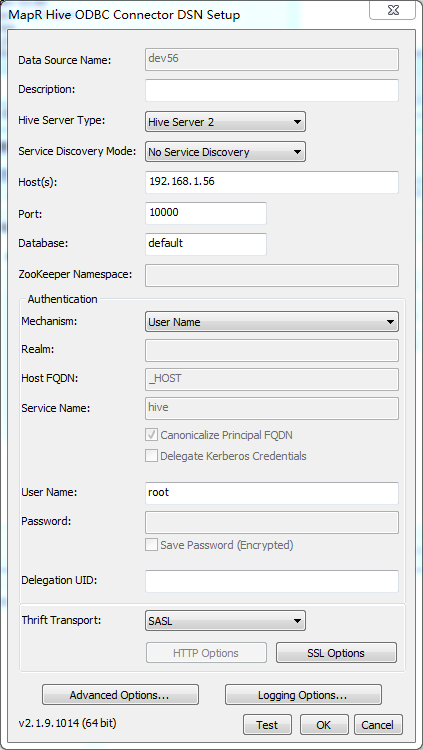
点击“Test”,你可能会遇到这样一个错误:User: root is not allowed to impersonate root.
此时,可以修改$HADOOP_HOME/etc/hadoop下的core-site.xml文件,在最底部加入下面配置:
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
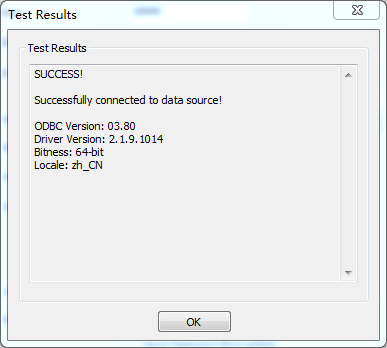
重启hadoop服务后,再次执行点击“Test”,成功后可以看到下面的界面:
如何重启Hadoop可以参看:linux上安装和配置Hadoop(单节点)
编写.Net Core控制台程序访问Hive
配置好了ODBC数据源之后,新建一个.Net Core项目,首先通过NuGet包管理器安装 System.Data.Odbc。
接下来编写代码就很容易了,都是熟悉的味道,我就直接贴上来了:
using System; using System.Data; using System.Data.Odbc; namespace HiveClient { class Program { static void Main(string[] args) { string dns = "DSN=dev56;UID=root;PWD="; using(HiveOdbcClient client = new HiveOdbcClient(dns)) { string sql = "Create TEMPORARY Table golds_log_tmp(user_id bigint, accounts string, change_type string, golds bigint, log_time int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'"; client.Excute(sql); sql = @"Insert into table golds_log_tmp values (3645787,'d159159(4172194)','游戏比赛奖励',1000,1526027152), (3641649, 'ffddbbgg55(4167873)', '游戏比赛奖励', 100, 1526027152), (684321, '763274471(850395)', '游戏比赛奖励', 100, 1526027152)"; client.Excute(sql); sql = "select * from golds_log_tmp"; var table = client.Query(sql); foreach(DataRow row in table.Rows) { Console.WriteLine($"{ row[0] }, {row[1]}, { row[2] }, { row[3] }, { row[4] }"); } } Console.ReadKey(); } } public class HiveOdbcClient:IDisposable { OdbcConnection _conn; public HiveOdbcClient(string dns) { _conn = new OdbcConnection(dns); _conn.Open(); } public void Excute(string sql) { OdbcCommand cmd = new OdbcCommand(sql, _conn); cmd.ExecuteNonQuery(); } public DataTable Query(string sql) { DataTable table = new DataTable(); OdbcDataAdapter adapter = new OdbcDataAdapter(sql, _conn); adapter.Fill(table); return table; } public void Dispose() { if (_conn != null) { _conn.Dispose(); } } } }
需要注意的是:执行Insert语句的部分执行的会比较久,因为通过Hive底层依然执行的是MapReduce,这是一个比较耗时的操作。如果此时查看linux的控制台,可以看到Hive的log输出:
Hadoop job information for Stage-1: number of mappers: 1; number of reducers:0 2018-07-25 17:59:40,983 Stage-1 map = 0%, reduce = 0% 2018-07-25 17:59:47,238 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.02sec MapReduce Total cumulative CPU time: 2 seconds 20 msec Ended Job = job_1532510920759_0002 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to directory hdfs://localhost:9000/tmp/hive/root/41c5d246-48b8-47e-a321-3726bdbc3e22/_tmp_space.db/e1545b51-4bdc-4859-b6d6-ebc09acf4e66/.hive-taging_hive_2018-07-25_17-59-32_779_3671872308271402381-3/-ext-10000 Loading data to table default.golds_log_tmp MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 2.02 sec HDFS Read: 5290 HDFS Write 259 SUCCESS Total MapReduce CPU Time Spent: 2 seconds 20 msec
至此,我们已经成功通过.Net编程的方式访问了Hive,创建了临时表、插入数据、并读取了数据。
感谢阅读,希望这篇文章能给你带来帮助!